遇到一个需求: 现在有一段 HTML 字符串, 需要拿到这里面所有的 img 标签的 src 属性.
HTML 字符串如下(已经过简化):
为了匹配 img 标签的 src 属性, 我使用的正则是 , 匹配结果如下:
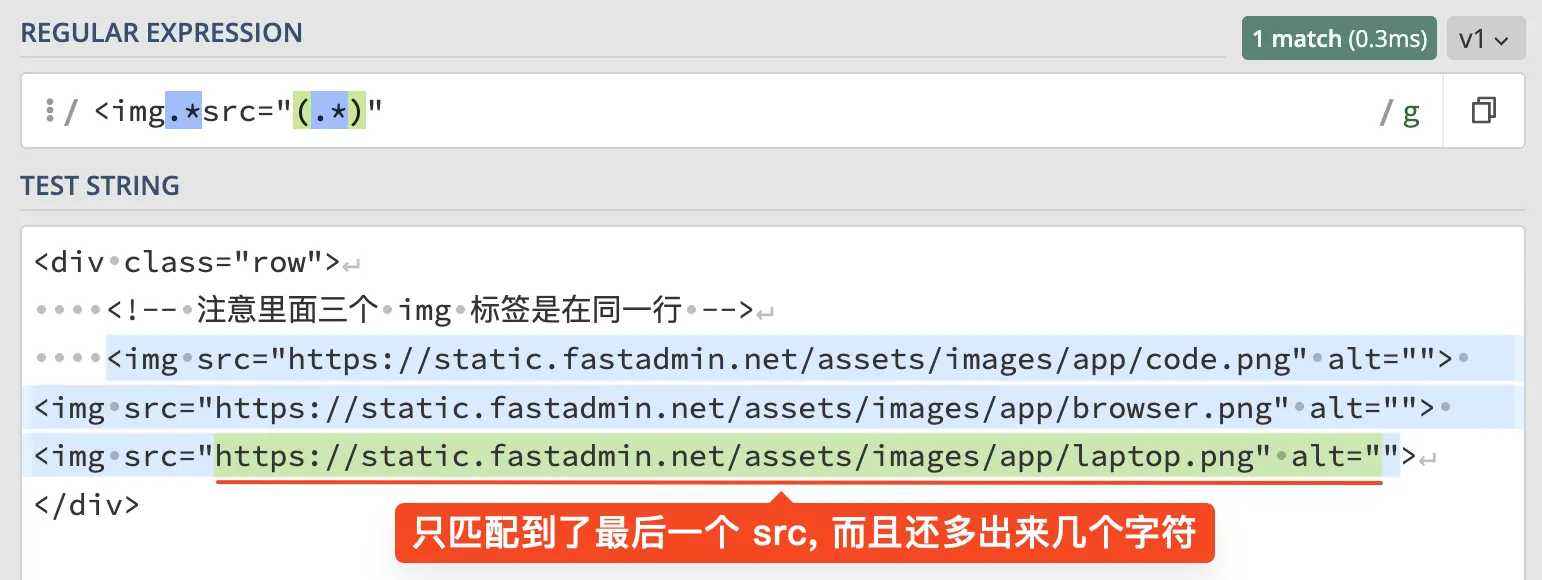
如图所示, 并没有按照期待中的匹配每个 src 属性值, 反而仅匹配到最后一个 src, 而且还多余匹配了几个字符. 图中使用的工具是匹配 src 属性之贪婪模式 - regex101, 您可以狠狠点击打开查看本示例.
经过多方查询(实际主要是问了 ChatGPT), 才知道这是因为正则默认是贪婪匹配模式导致的.
什么是贪婪匹配
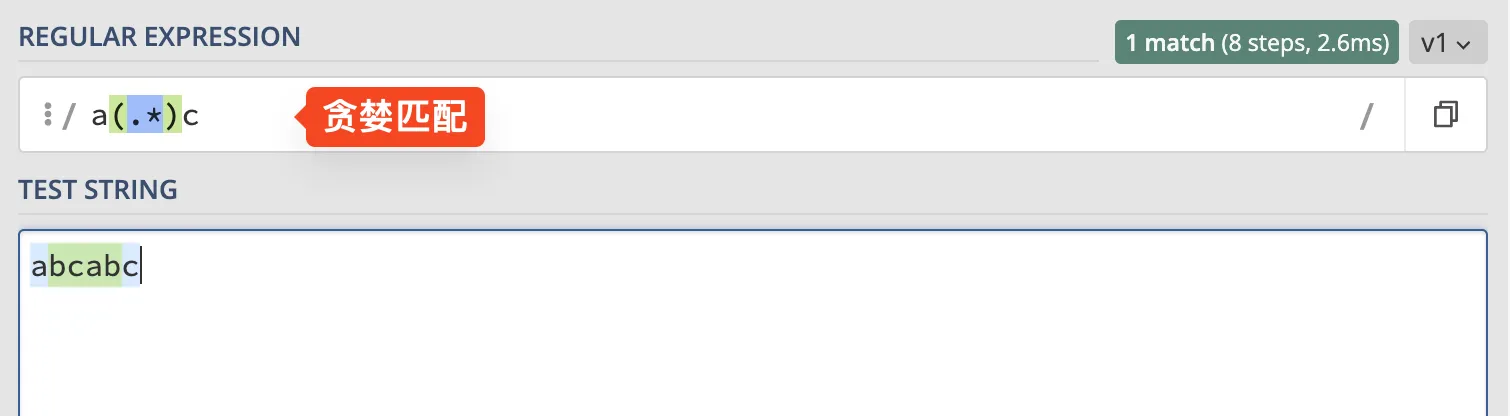
顾名思义, "贪婪"就是尽可能多的匹配符合条件的字符. 举个例子 🌰, 现在有一个字符串 , 正则是 , 你认为 会匹配哪些字符呢? 是 还是 呢?
答案是 , 实际两个答案都符合正则匹配, 但是因为"贪婪"的缘故, 所以最后匹配到的结果是"最多"的那个, 也就是 .
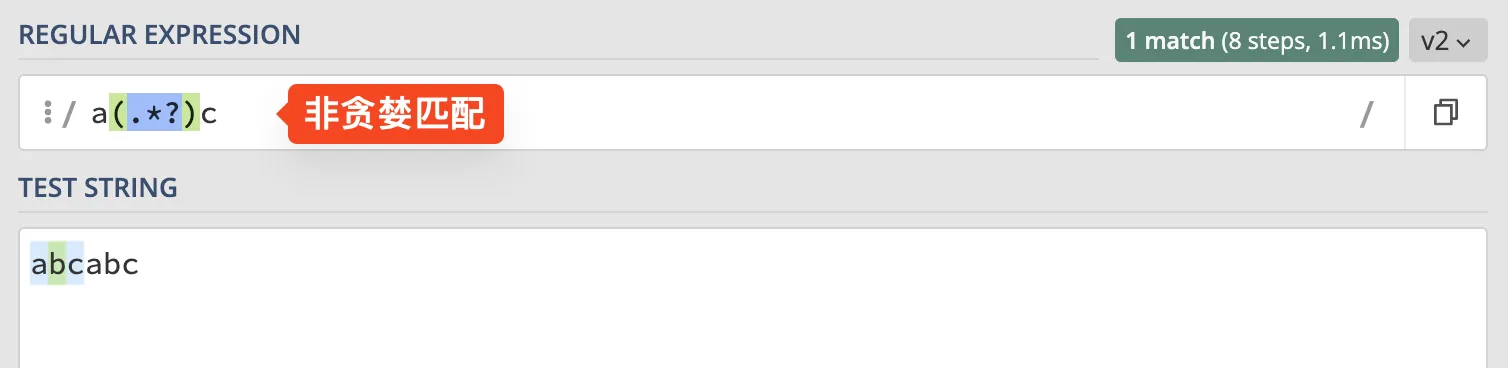
如何匹配最少那个呢? 那就要使用"非贪婪模式"了. 将刚才的正则改为 就是非贪婪模式了, 这样就是只匹配第一次出现的 了.
这两个例子也都可以点击查看:
贪婪匹配和非贪婪匹配的规则
正则匹配时,如果遇到下面这些标识符,代表是贪婪匹配,会尽可能多的去匹配内容:
,,,,,
与之对应的非贪婪匹配标识符如下:
,,,,,
可以看到,非贪婪模式的标识符其实就是在贪婪模式的标识符后面加上一个
最终代码
因此只需要将一开始匹配 src 属性的正则改为非贪婪模式即可:
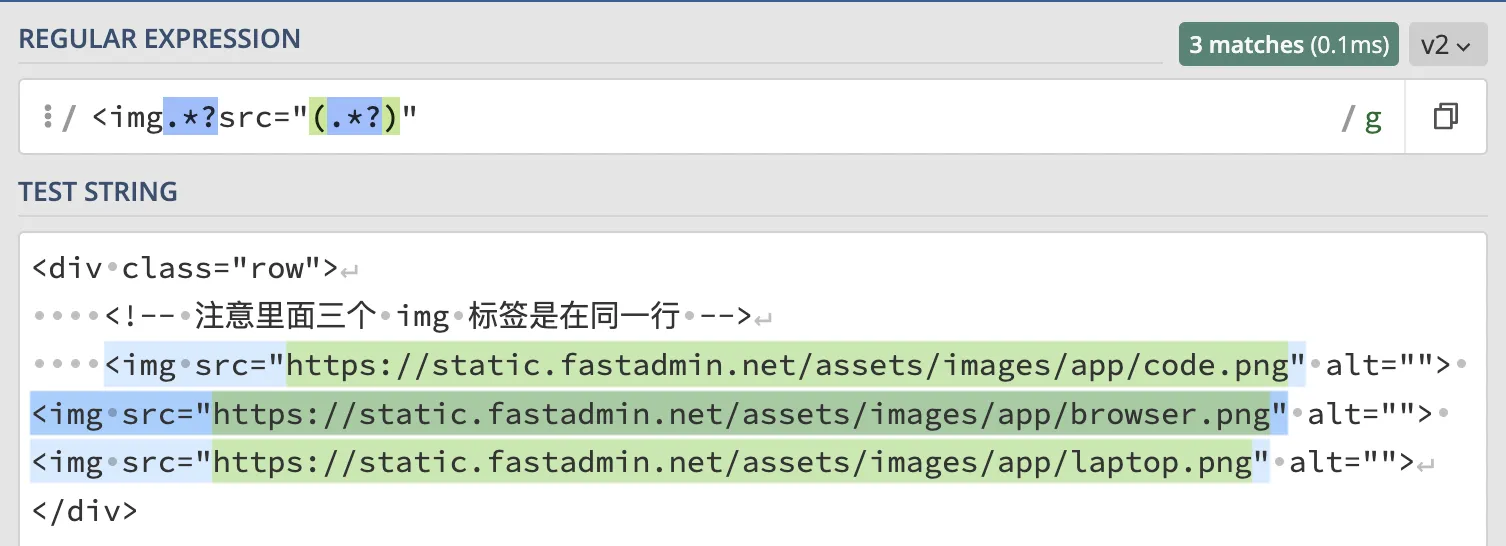
结果和预期相同, 匹配到了全部的 src 属性, 您可以点击查看: 匹配 src 属性之非贪婪模式 - regex101
最后完整代码如下: